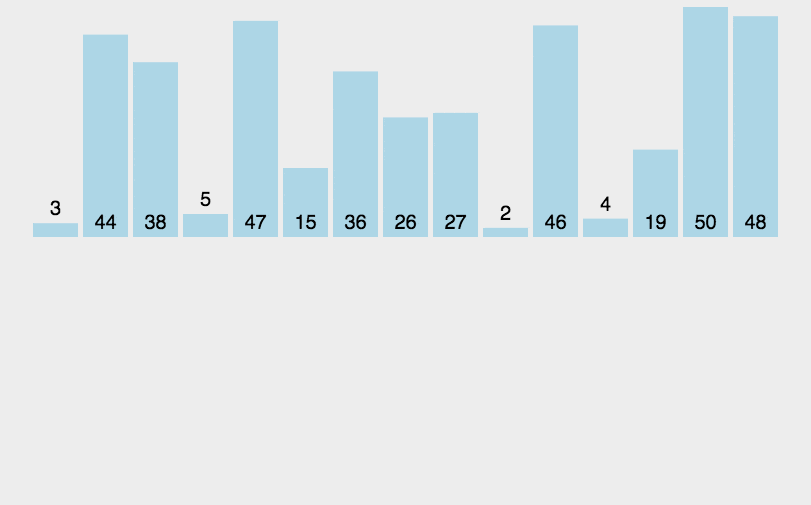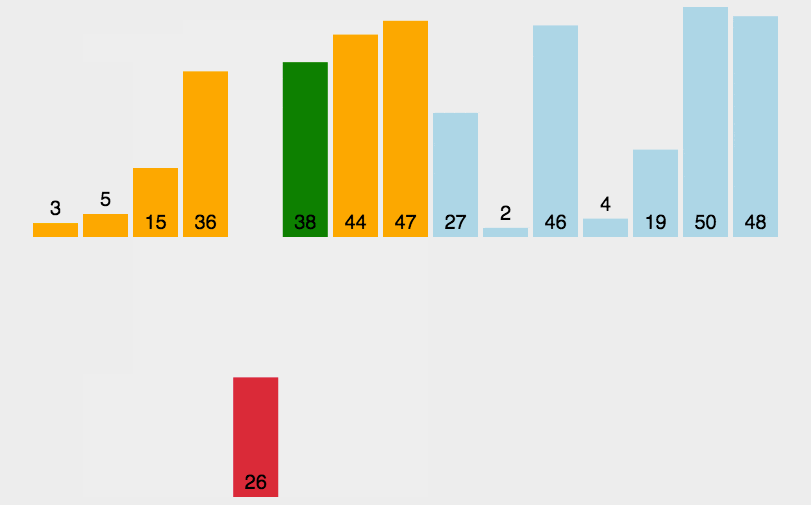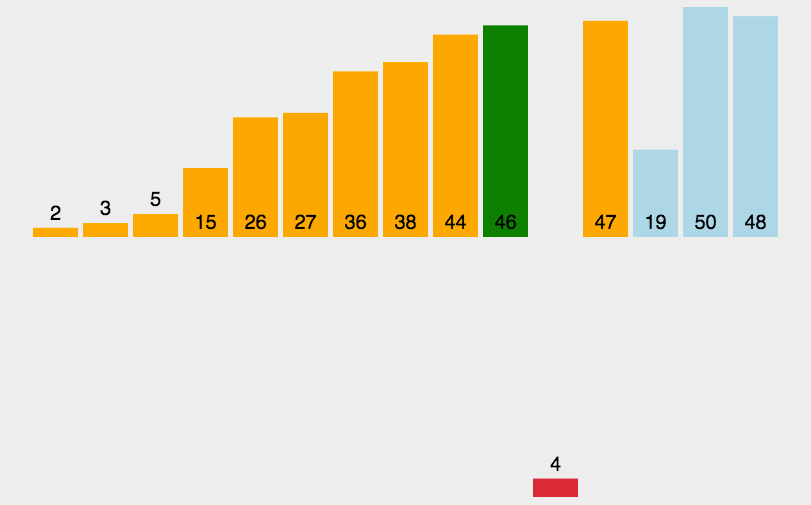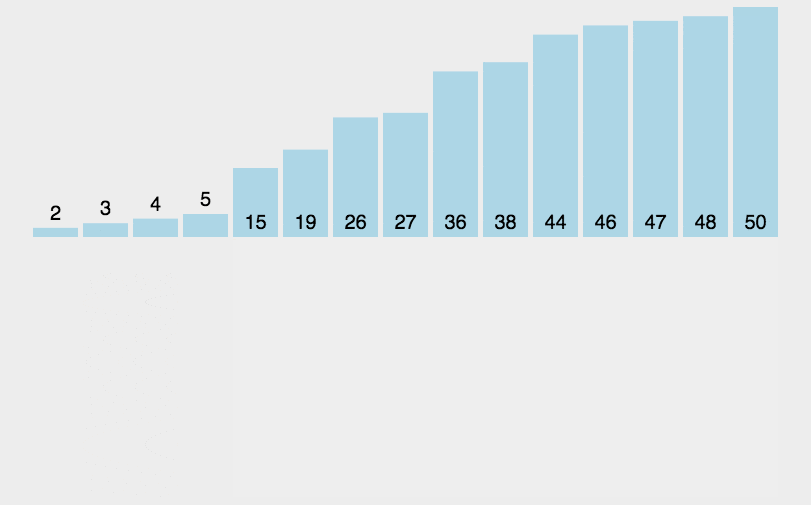
However, it is not possible to do so in JavaScript, as the recursion goes too deep for the language to handle. 然而,在 JavaScript 中这种方式不太可行,因为这个算法的递归深度对它来讲太深了。
private static void sort(int[] arr, int left, int right) { if (left == right) {//左右相等,那么只剩下一个元素退出 return; } int middle = left + (right - left) / 2;//取中位数的左边 sort(arr, left, middle);//左手边再排序 sort(arr, middle + 1, right);//右手边再排序 merge(arr, left, middle + 1, right);//已经排序的结果合并 }
private static void merge(int[] arr, int left, int mid, int right) { int[] temp = new int[right - left + 1];//为什么要加1,假如 right = left,至少需要一个空间放元素 int i = left; int j = mid; int n = 0; while (i < mid && j < right + 1) {//边界需要确定好,因为这边都是闭区间 //那边小取那边 if (arr[i] <= arr[j]) { temp[n] = arr[i]; i++; n++; } else { temp[n] = arr[j]; j++; n++; } } //将剩下的集合直接拷贝过去 while (i < mid) { temp[n] = arr[i]; i++; n++; } while (j < right + 1) { temp[n] = arr[j]; j++; n++; } //将多余集合拷贝回去原数组 i = left;//找准开始下标 for (int value : temp) { arr[i] = value; i++; } } }
6、快速排序
快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要 Ο(nlogn) 次比较。在最坏状况下则需要 Ο(n^2) 次比较,但这种状况并不常见。事实上,快速排序通常明显比其他 Ο(nlogn) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。
快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
快速排序的名字起的是简单粗暴,因为一听到这个名字你就知道它存在的意义,就是快,而且效率高!它是处理大数据最快的排序算法之一了。虽然 Worst Case 的时间复杂度达到了 O(n²),但是人家就是优秀,在大多数情况下都比平均时间复杂度为 O(n logn) 的排序算法表现要更好,可是这是为什么呢,我也不知道。好在我的强迫症又犯了,查了 N 多资料终于在《算法艺术与信息学竞赛》上找到了满意的答案:
private static void quickSort(int[] arr, int left, int right) { if (left < right) {//只有在一个区间里,才有排序的意义 int midIndex = partition(arr, left, right); //左右区间都是闭区间,所以不应该包括midIndex quickSort(arr, left, midIndex - 1); quickSort(arr, midIndex + 1, right); } }
/** * 在 [left,right]区间随意找一个元素,确立这个元素在这个区间内的位置,并返回下标 * 快速排序之所以快,就是因为在这个确立下标的过程中,做了一次排序定位 */ private static int partition(int[] arr, int left, int right) { //获取区间里任意的一个基准值,为了简化代码,所以使用第一个值 int base = arr[left]; int i = left; int j = right; //使用左右指针,使i、j逐渐相遇 while (i != j) {//假如i、j没有相遇 while (i != j && arr[j] >= base) {//如果当前j的值大于等于base那么就j缩小 j--; } while (i != j && arr[i] <= base) {//如果当前i的值小于于等于base那么就i增小 i++; } if (i != j) { swap(arr, i, j); } } //当前i、j已经相遇,那么就交互i以及base的数值 arr[left] = arr[i]; arr[i] = base; //此时i的值就是base在数组确立不动的下标 return i; }
//参数交换方法 private static void swap(int[] arr, int i, int j) { int temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; }